
EV-SegNet-paper笔记
最近在做一些关于高速视觉感知的课题,自己主要是将工作集中到了Event-camera的相关工作上来,一周内吧,也没读太多的文献,工作效率也不是特别的高。趁着周日将这周看的论文先整理一下。
主要的贡献
- 给出了一种CNN框架,能够处理事件相机数据
- 如何生成事件相机带有标签的数据集
- 比较采用不同事件相机数据的表现性能
创新点
-
崭新的事件相机数据编码方式,基于Xception,六通道,空间结合时间的网络输入。
两个通道:正事件的直方图、负事件的直方图(->承载空间信息
四个通道:正事件的均值、均方差、负事件的均值、均方差->承载事件轴信息,而不仅仅是时间戳信息
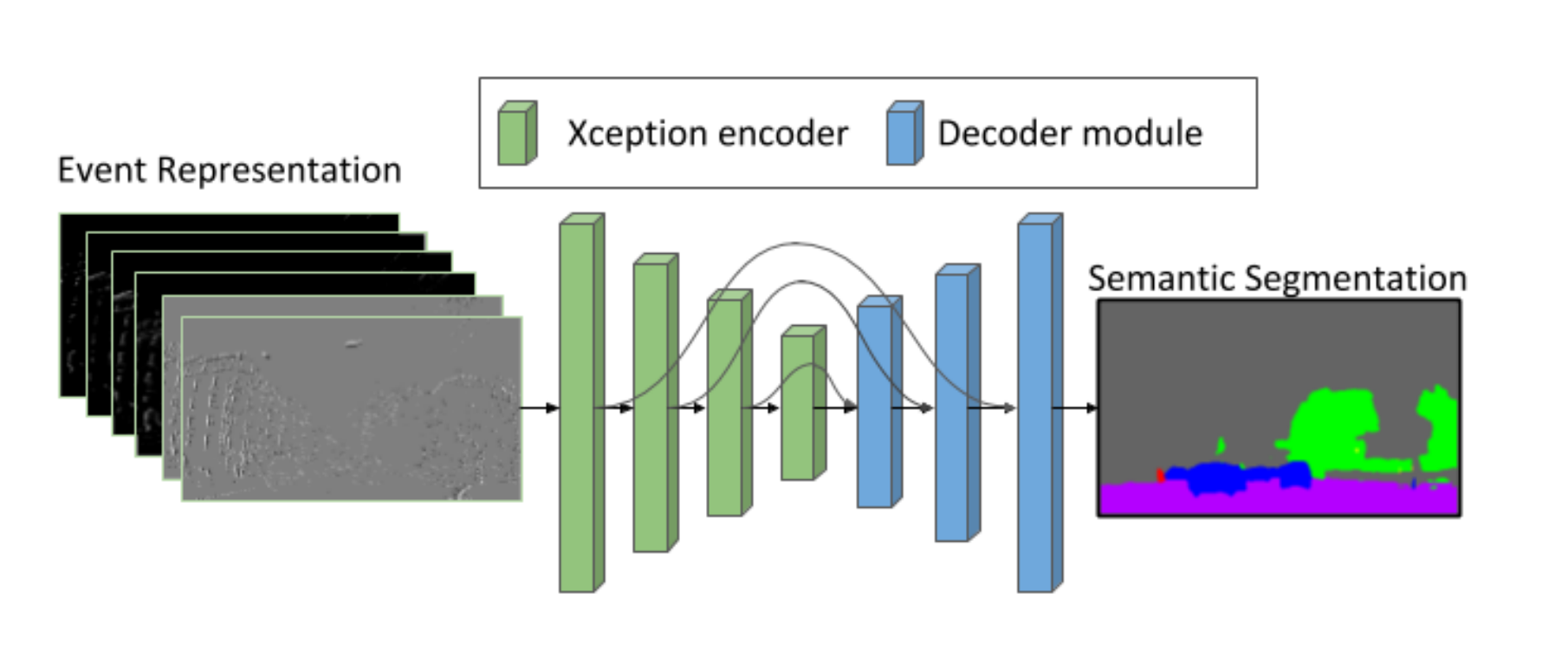
-
用Cityscape所有数据集训练出来的CNN,对现有挑选出来的CityScapes打上标签,作为伪标签(论文中以此作为GT),以伪标签训练事件相机数据的网络。
数据集的获得
挑选DDD17数据集(事件相机、RGB相机同步)其中的一部分(高对比度、无过曝)作为标签数据集,以所有灰度图像跑出来的灰度模型去识别挑选出的灰度序列,得到的标签作为伪标签训练事件相机。这里它提出来:灰度图像语义分割得到了83%的MIoU,与最高的92%相比,证明了这种方式的可靠性。
这里鸿羽给了我一些指导,这种方式得到的数据集一般是没有问题的。但是也给我们提供了另外的一种思路:先去网络去学习边缘,因为本来我们的得到的边缘标签就是不精确的,也就无需考虑标签的置信度问题了,然后再根据边缘去学习分割
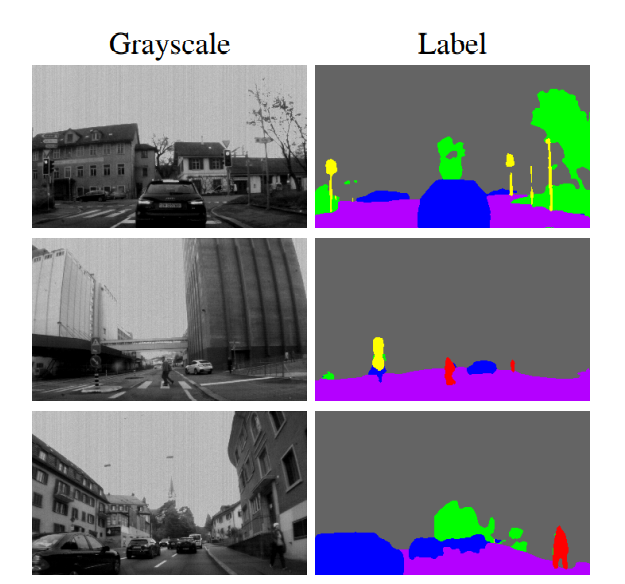
这里就是生成的Ev-Seg的数据集的标签,采用灰度图训练出来的CNN得到的标签。
对比
这里对比采用了两个指标,用来评估模型性能。
分别对比了三种类型事件数据编码的模型性能,包括基本密度编码(Basic dense encoding)、时间密集编码(Temporal dense encoding),和本论文的六通道编码。
| Input representation | Accuracy(50ms) | MIoU(50ms) | Accuracy(10ms) | MIoU(10ms) | Accuracy(250ms) | MIoU(250ms) |
|---|---|---|---|---|---|---|
| Basic dense encoding | 88.85 | 53.07 | 85.06 | 42.93 | 87.09 | 45.66 |
| Temporal dense encoding | 88.96 | 52.32 | 86.35 | 43.65 | 85.89 | 45.12 |
| Ours | 89.76 | 54.81 | 86.46 | 45.85 | 87.72 | 47.56 |
| Grayscale | 94.67 | 64.98 | 94.67 | 64.98 | 94.67 | 64.98 |
| Grayscale & Ours | 95.22 | 68.36 | 95.18 | 67.95 | 95.29 | 68.26 |
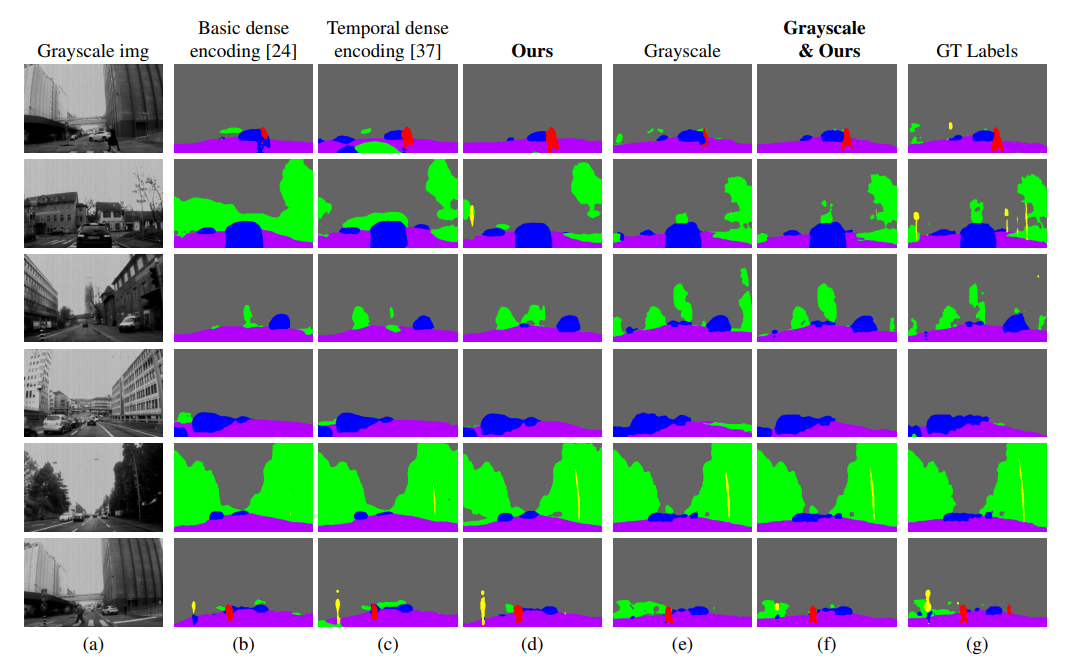
不仅对比了不同编码方式的性能(这里是定量给出了指标),还对比了不同积分时间内的分割性能(这里只采用了可视化的方式,并没有定量地给出)。

论文指出,在不同的积分时间下,对应着不同的速度,该模型的性能依旧表现良好。
结论
Xception-based encoder-decoder用于处理事件相机数据的语义分割
为DDD17数据集打上标签
优缺点
缺点
事件数据无法捕捉静态信息
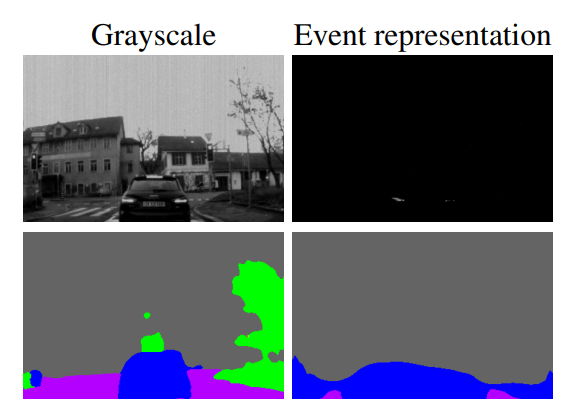
优点
在极度光照条件下,事件相机对于数据的捕捉更为敏感

个人总结
个人觉得,这篇文章比较新颖的点主要是在事件相机的编码方式,事件相机作为比较新颖的图像设备,采用的是与传统相机截然不同的数据存储方式。目前RGB图像的语义分割最常用的也是用的网络的方式进行训练,也是做到了很好的效果。可是对于事件相机的数据来讲,它无法直接放入到现有的这些网络当中,并且目前非常缺少对应的打好标签的事件相机数据集,这也是普遍存在的问题:语义分割训练的标签很大程度依赖于RGB相机分割出来的伪标签。
我个人目前想做的点在于,用事件相机数据去进行城市场景下的语义分割,就像Ev-Seg所作的这样,但是该论文更侧重的创新点在于六通道的编解码方式,以及以事件相机数据为输入的分割网络。我们计划采用RGB相机的数据进行标签标记,训练事件相机数据,最终实现对于事件相机数据的语义分割。这篇论文给我的提示点在于:
- 网络的输入部分可以做文章,是否可以结合RGB与Event作为训练网络的输入
- 事件相机数据如何应用